
Should you’re studying this, you’ve seemingly encountered the “Crawled – At the moment Not Listed” error in Google Search Console.
Of the 213 Google Search Console profiles I entry, 89% have the “Crawled – At the moment Not Listed” error listed of their Google Search Console accounts. (Sure, I counted).
As any web optimization skilled will let you know, it might really feel like the tip of the world while you don’t know the right way to resolve the error, leading to a shriveled backlog of technical errors you’ll get to in the future.
Earlier than you toss this error within the pile to evaluation later, take a step again and assess the information. I’ve rounded up seven fixes for the most typical web optimization debacles I’ve seen so you may salvage your web sites and save a bit of time.
Why would Google crawl a web page however not index it?
There are a number of the explanation why a web page could also be crawled however not listed.
In Google’s web optimization Workplace Hours in March 2022, John Mueller highlighted a few of the frequent the explanation why customers may even see the error “Crawled – At the moment not listed,” like:
- Error code like a 404 error.
- Noindex tag on the web page.
- Duplicate content material.
Mueller later said one more reason:
- “We crawl one thing, however by the point we get to indexing, we resolve we truly need to get one thing else from the web site as a substitute.”
Should you learn between the strains, I interpreted this as Google classifying your content material as unhelpful, signaling a top quality challenge.
With Google’s AI Overview announcement, Google is reducing the crawl budget, so optimizing your crawl funds with high quality content material is a excessive precedence.
This ties into what Gary Illyes talked about on X, the place your poor-quality content is replaced with higher-quality content.
How do I repair ‘Crawled – At the moment not listed’ in Google Search Console?
1. Manually evaluation all of the pages flagged within the report
First, I manually reviewed all of the pages flagged within the Google Search Console “Crawled – presently not listed” report.
To entry the report, go to Google Search Console > Pages, then look below the part “Why pages aren’t listed.”
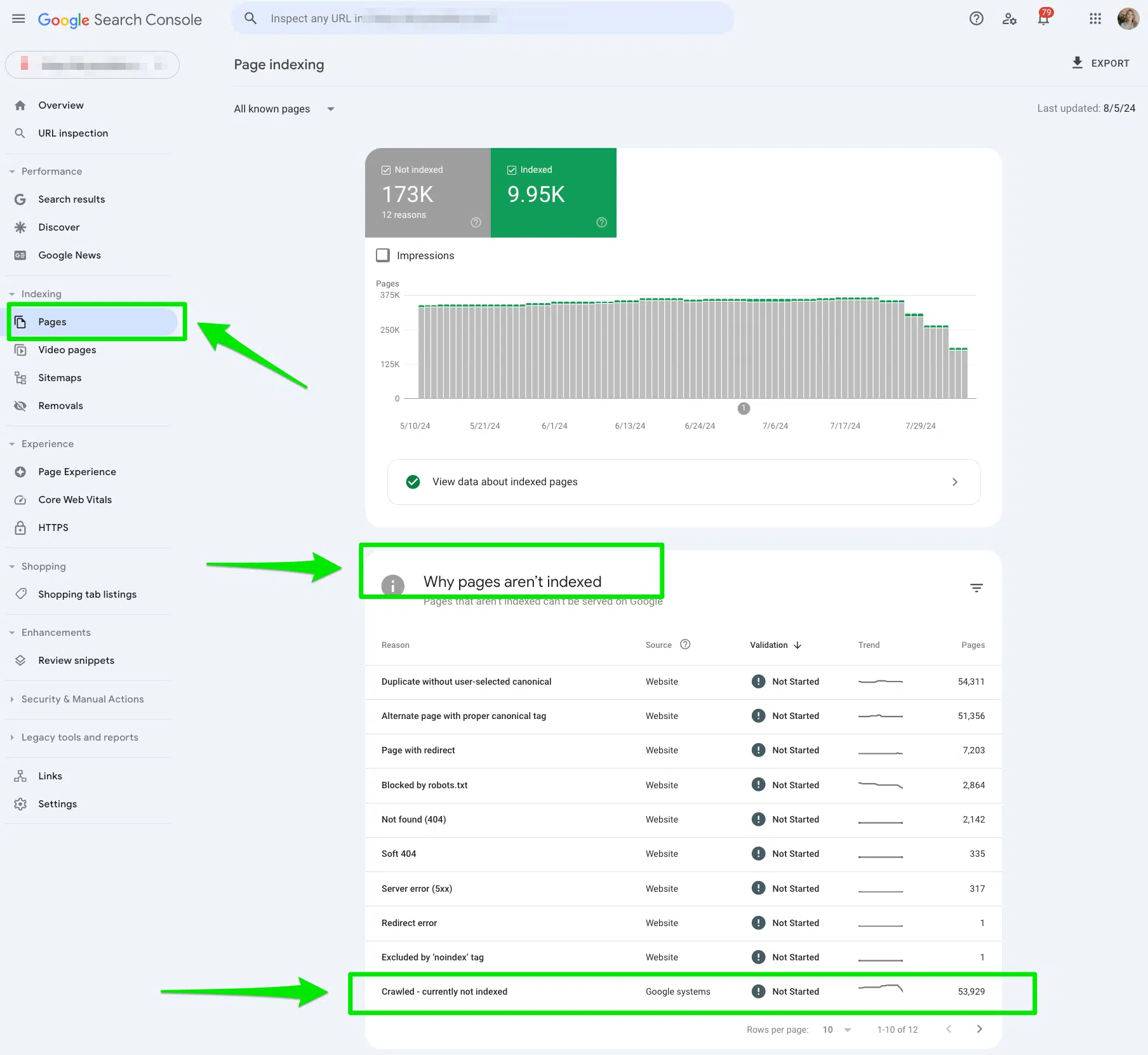
As soon as within the report, you may export the information to Google Sheets, Excel, or CSV to filter it.
Then, there are two issues I begin to dive into:
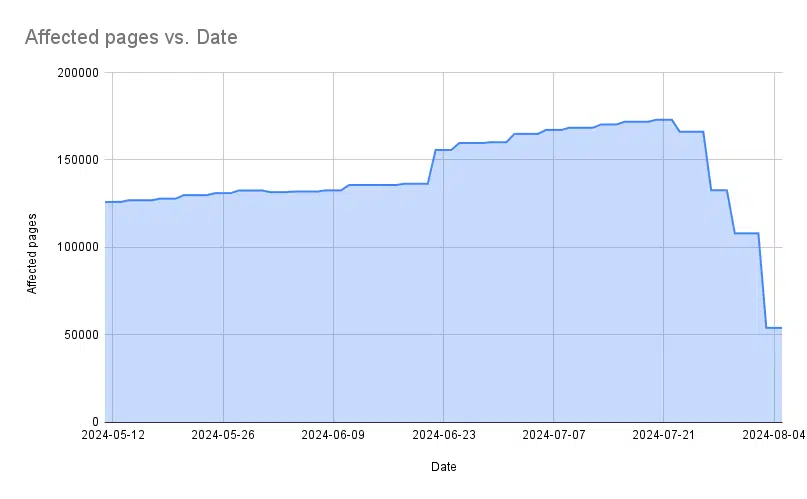
- Dates in comparison with affected pages: I’m seeking to see if the pattern line is rising or reducing. If it’s lowering, it indicators that we might have fastened the problem.
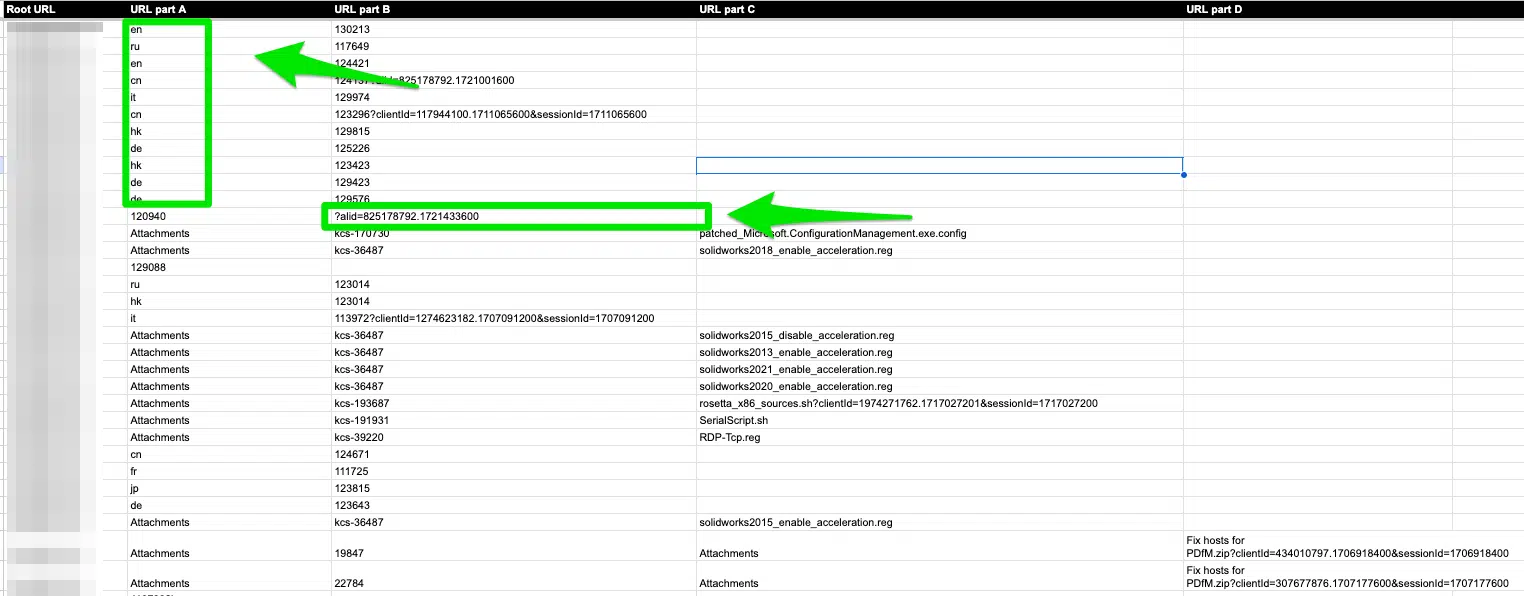
- URL construction: I’m seeking to see if there’s a typical sample between parameter URLs, language subfolders, or related URLs. I take advantage of the “Break up textual content to columns” possibility in Google Sheets. This helps me establish patterns. As you may see beneath, I already know I want to research two potential points: worldwide web optimization and canonical tags.
2. Begin an inner hyperlink hierarchy implementation undertaking
Should you’ve ever launched a chunk of content material with out an inner hyperlink, or simply plain forgot (ahem), you’ve in all probability requested your self why your content material isn’t performing.
Whenever you spend hours, days, and generally months prepping a golden nugget of content material solely to see it as a tragic, damaged mess with no site visitors, it’s not enjoyable.
Thankfully, if there are methods to salvage the content material and make it a better high quality piece, Google is able to index.
All you want is a bit of inner hyperlink hierarchy implementation undertaking.
I take not less than two weeks to map out inner hyperlink alternatives by figuring out inner pages to hyperlink from and to.
To search out high quality inner hyperlink possibilities, I leverage Google’s website search operators like “Web site:mydomain.com Key phrase.”
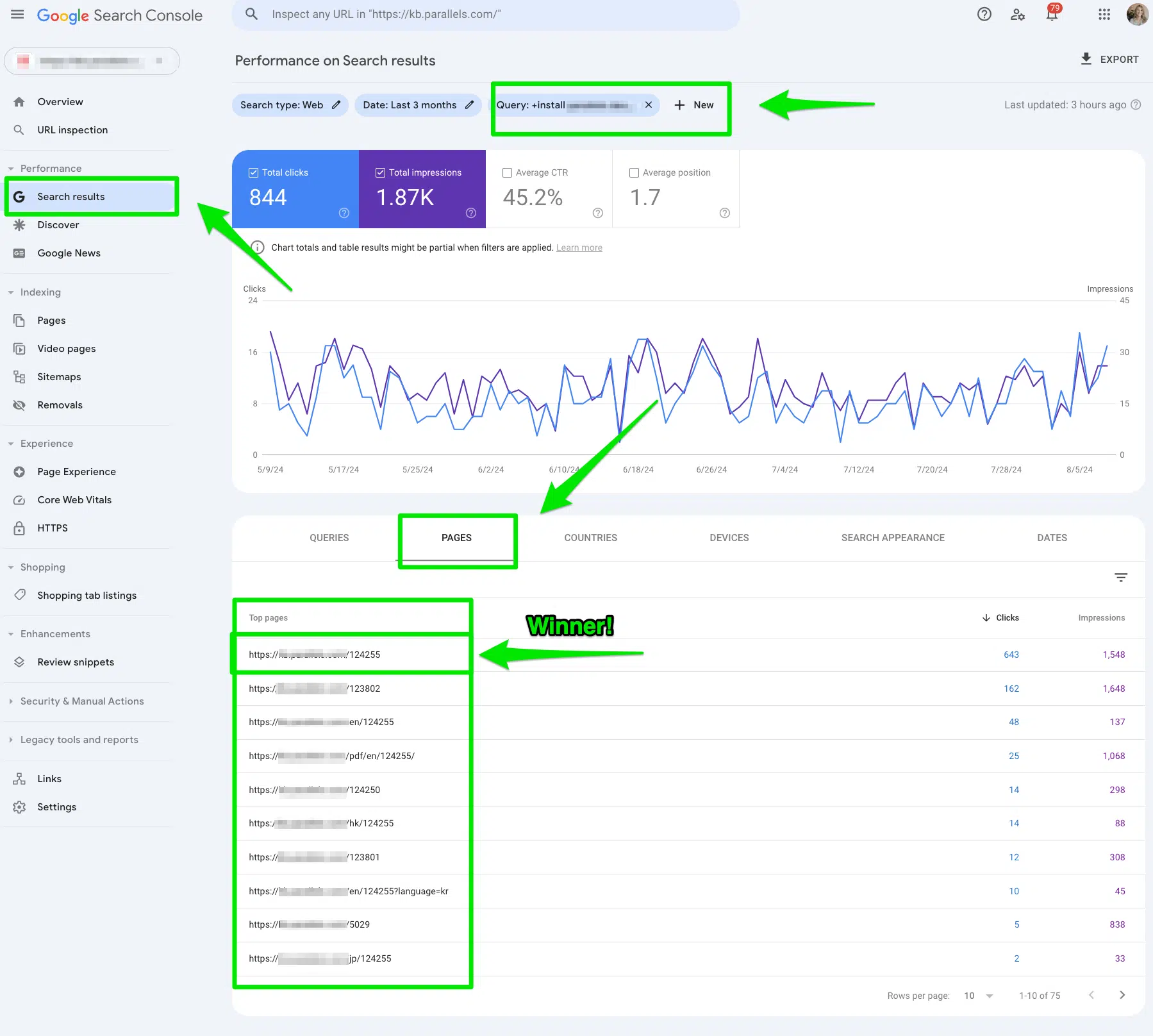
As soon as I collect an inventory of 5-10 pages I’d prefer to hyperlink to and from, I test for key phrase cannibalization in Google Search Console.
Go to Search Outcomes > kind of your Question > filter by pages in Google Search Console.
Then, I choose the web page that I need to rank for these phrases as my major inner hyperlink.
Keep in mind your web site’s construction. If there are numerous pages not listed within the navigation, engines like google might not discover them due to your website construction.
3. Add self-referencing canonical tags to fight duplicate content material
The following battle I purpose to win is eradicating any duplicate content material within the report.
Add self-referencing canonical tags to parameter URLs to keep away from duplicate content material.
For instance, let’s say this URL was listed in my report for “Crawled – At the moment not listed”:
- www.annalovesburritos.com/en/120313
The canonical tag must be self-referencing and seem like this:
- www.annalovesburritos.com/en/120313
However generally, I run into points the place the canonical tag seems like this
- www.annalovesburritos.com/120313
See something lacking? The subfolder is lacking.
One other problem I face is when the canonical tag for a parameter URL is listed.
Let’s use the instance above:
- www.annalovesburritos.com/en/120313
And we add a parameter:
- www.annalovesburritos.com/en/120313?clientID-12345
However while you test the canonical tag, it reveals the parameter URL:
- www.annalovesburritos.com/en/120313?clientID-12345
You don’t want to record your parameter URL as your canonical tag to keep away from duplicate content material.
So, when you see this:
You’ll need to change it to this:
5. Double-check your hreflang tags are appropriate
One other fast win to assist get your content material crawled and listed is double-checking your hreflang tags.
You’ll need to guarantee your nation and language codes are correct.
However you’ll additionally need to test that the content material exists within the language it says it does.
I can’t let you know what number of occasions I’ve come throughout hreflang that claims it’s in Japanese, however after I truly go to the Japanese internet web page, it’s written in English.
That is thought-about duplicate content material, and Google will seemingly by no means index it.
6. Audit your XML sitemap
When you’ve cleaned up the canonical and hreflang tags, test your XML sitemap.
You need to make sure that all of the pages listed in your XML sitemap are 200 standing pages with self-referencing canonical tags and localized variations listed below the first model.
When you’ve got key cash pages, you may create a short lived XML sitemap that focuses solely on the pages listed within the “Crawled–At the moment not listed” report.
7. Submit fastened URLs to the URL inspection device
The ultimate step is manually submitting all of your fastened URLs into the URL inspection device in Google Search Console.
Sometimes, I’ll select batches of 10-20 URLs and see how Google treats these.
Understand that simply since you did every part proper doesn’t imply Google will repair the problem. It turns into a ready sport for Google to recrawl every URL and decide if it’s higher than an current web page.
Useful content material is the best way to keep away from the ‘Crawled – At the moment not listed’ error in Google Search Console
Let’s face it: Google seemingly shouldn’t be indexing your content material due to high quality points.
Keep in mind, simply because a web page is listed in the present day doesn’t assure it is going to be listed tomorrow. Google will change the way it evaluates content material, and you should adapt to that change.
You’re at all times monitoring your content material and searching for methods to implement enhancements.
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search group. Our contributors work below the oversight of the editorial staff and contributions are checked for high quality and relevance to our readers. The opinions they specific are their very own.