
In a latest LinkedIn publish, Gary Illyes, Analyst at Google, highlights lesser-known features of the robots.txt file because it marks its thirtieth 12 months.
The robots.txt file, an internet crawling and indexing element, has been a mainstay of search engine optimisation practices since its inception.
Right here’s one of many explanation why it stays helpful.
Strong Error Dealing with
Illyes emphasised the file’s resilience to errors.
“robots.txt is nearly error free,” Illyes stated.
In his publish, he defined that robots.txt parsers are designed to ignore most mistakes with out compromising performance.
This implies the file will proceed working even in the event you unintentionally embody unrelated content material or misspell directives.
He elaborated that parsers usually acknowledge and course of key directives comparable to user-agent, permit, and disallow whereas overlooking unrecognized content material.
Surprising Characteristic: Line Instructions
Illyes identified the presence of line feedback in robots.txt recordsdata, a function he discovered puzzling given the file’s error-tolerant nature.
He invited the search engine optimisation group to invest on the explanations behind this inclusion.
Responses To Illyes’ Publish
The search engine optimisation group’s response to Illyes’ publish gives further context on the sensible implications of robots.txt’s error tolerance and using line feedback.
Andrew C., Founding father of Optimisey, highlighted the utility of line feedback for inner communication, stating:
“When engaged on web sites you may see a line remark as a be aware from the Dev about what they need that ‘disallow’ line within the file to do.”
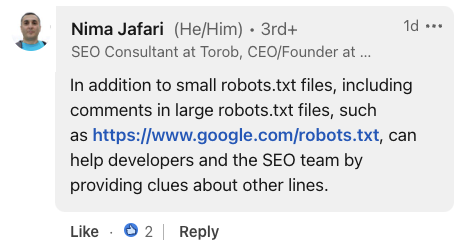
Nima Jafari, an search engine optimisation Marketing consultant, emphasised the worth of feedback in large-scale implementations.
He famous that for intensive robots.txt recordsdata, feedback can “assist builders and the search engine optimisation group by offering clues about different traces.”
 Screenshot from LinkedIn, July 2024.
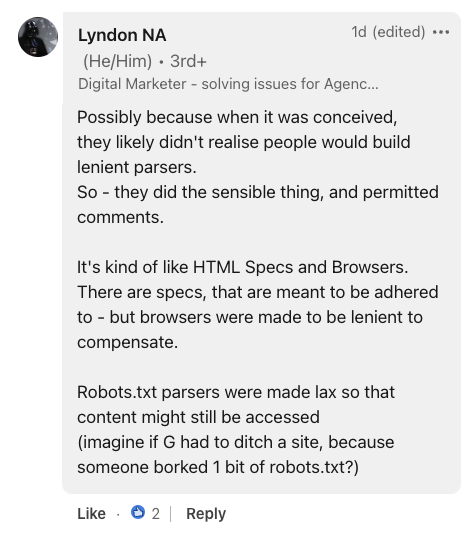
Screenshot from LinkedIn, July 2024.Offering historic context, Lyndon NA, a digital marketer, in contrast robots.txt to HTML specs and browsers.
He recommended that the file’s error tolerance was probably an intentional design alternative, stating:
“Robots.txt parsers had been made lax in order that content material may nonetheless be accessed (think about if G needed to ditch a web site, as a result of somebody borked 1 little bit of robots.txt?).”
 Screenshot from LinkedIn, July 2024.
Screenshot from LinkedIn, July 2024.Why SEJ Cares
Understanding the nuances of the robots.txt file will help you optimize websites higher.
Whereas the file’s error-tolerant nature is mostly helpful, it may probably result in missed points if not managed rigorously.
What To Do With This Data
- Evaluation your robots.txt file: Guarantee it accommodates solely mandatory directives and is free from potential errors or misconfigurations.
- Be cautious with spelling: Whereas parsers might ignore misspellings, this might lead to unintended crawling behaviors.
- Leverage line feedback: Feedback can be utilized to doc your robots.txt file for future reference.
Featured Picture: sutadism/Shutterstock