
It must be clear to everybody that the Google documentation leak and the public documents from antitrust hearings do not likely inform us precisely how the rankings work.
The construction of natural search outcomes is now so advanced – not least attributable to using machine studying – that even the Google workers who work on the rating algorithms say they will not clarify why a success is at one or two. We have no idea the weighting of the various indicators and the precise interaction.
Nonetheless, it is very important familiarize your self with the construction of the search engine to grasp why well-optimized pages don’t rank or, conversely, why seemingly quick and non-optimized outcomes typically seem on the high of the rankings. An important side is that you want to broaden your view of what’s actually essential.
All the knowledge obtainable clearly reveals that. Anybody who’s even marginally concerned with rating ought to incorporate these findings into their very own mindset. You will notice your web sites from a totally totally different perspective and incorporate extra metrics into your analyses, planning and choices.
To be sincere, this can be very troublesome to attract a very legitimate image of the programs’ construction. The data on the internet is kind of totally different in its interpretation and typically differs in phrases, though the identical factor is supposed.
An instance: The system answerable for constructing a SERP (search outcomes web page) that optimizes house use is known as Tangram. In some Google paperwork, nevertheless, it’s also known as Tetris, which might be a reference to the well-known recreation.
Over weeks of detailed work, I’ve seen, analyzed, structured, discarded and restructured nearly 100 paperwork many instances.
This text isn’t supposed to be exhaustive or strictly correct. It represents my finest effort (i.e., “to the most effective of my data and perception”) and a little bit of Inspector Columbo’s investigative spirit. The result’s what you see right here.
A brand new doc ready for Googlebot’s go to
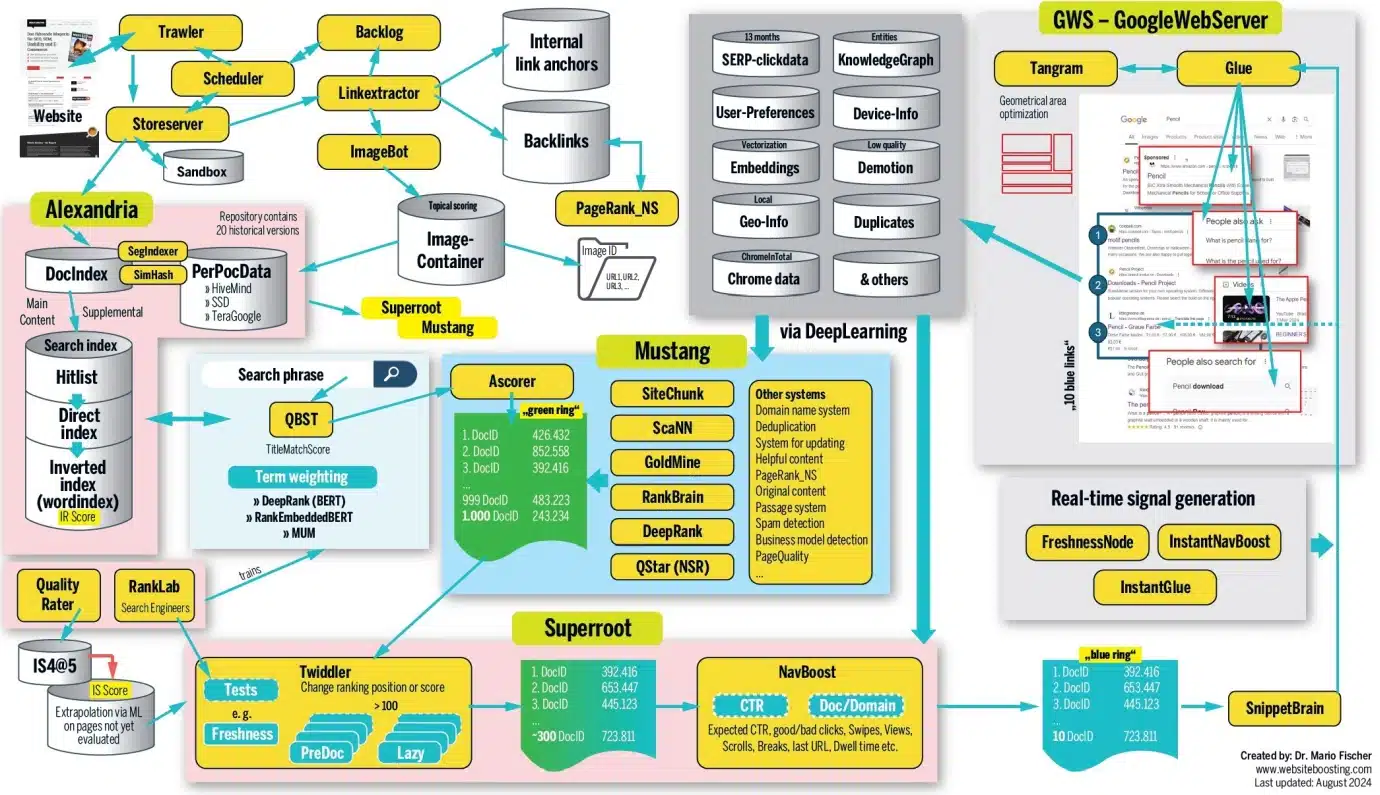
Once you publish a brand new web site, it isn’t listed instantly. Google should first develop into conscious of the URL. This normally occurs both through an up to date sitemap or through a hyperlink positioned there from an already-known URL.
Incessantly visited pages, such because the homepage, naturally deliver this hyperlink data to Google’s consideration extra rapidly.
The trawler system retrieves new content material and retains monitor of when to revisit the URL to verify for updates. That is managed by a element referred to as the scheduler. The shop server decides whether or not the URL is forwarded or whether or not it’s positioned within the sandbox.
Google denies the existence of this field, however the current leaks recommend that (suspected) spam websites and low-value websites are positioned there. It must be talked about that Google apparently forwards among the spam, in all probability for additional evaluation to coach its algorithms.
Our fictitious doc passes this barrier. Outgoing hyperlinks from our doc are extracted and sorted in line with inner or exterior outgoing. Different programs primarily use this data for hyperlink evaluation and PageRank calculation. (Extra on this later.)
Hyperlinks to pictures are transferred to the ImageBot, which calls them up, typically with a big delay, and they’re positioned (along with similar or comparable photos) in a picture container. Trawler apparently makes use of its personal PageRank to regulate the crawl frequency. If a web site has extra site visitors, this crawl frequency will increase (ClientTrafficFraction).
Alexandria: The nice library
Google’s indexing system, referred to as Alexandria, assigns a novel DocID to every piece of content material. If the content material is already recognized, corresponding to within the case of duplicates, a brand new ID isn’t created; as a substitute, the URL is linked to the present DocID.
Essential: Google differentiates between a URL and a doc. A doc could be made up of a number of URLs that comprise comparable content material, together with totally different language variations, if they’re correctly marked. URLs from different domains are additionally sorted right here. All of the indicators from these URLs are utilized through the widespread DocID.
For duplicate content material, Google selects the canonical model, which seems in search rankings. This additionally explains why different URLs could typically rank equally; the dedication of the “unique” (canonical) URL can change over time.

As there may be solely this one model of our doc on the internet, it’s given its personal DocID.
Particular person segments of our website are looked for related key phrase phrases and pushed into the search index. There, the “hit listing” (all of the essential phrases on the web page) is first despatched to the direct index, which summarizes the key phrases that happen a number of instances per web page.
Now an essential step takes place. The person key phrase phrases are built-in into the phrase catalog of the inverted index (phrase index). The phrase pencil and all essential paperwork containing this phrase are already listed there.
In easy phrases, as our doc prominently accommodates the phrase pencil a number of instances, it’s now listed within the phrase index with its DocID beneath the entry “pencil.”
The DocID is assigned an algorithmically calculated IR (data retrieval) rating for pencil, later used for inclusion within the Posting Checklist. In our doc, for instance, the phrase pencil has been marked in daring within the textual content and is contained in H1 (saved in AvrTermWeight). Such and different indicators enhance the IR rating.
Google strikes paperwork thought of essential to the so-called HiveMind, i.e., the primary reminiscence. Google makes use of each quick SSDs and traditional HDDs (known as TeraGoogle) for long-term storage of knowledge that doesn’t require fast entry. Paperwork and indicators are saved in the primary reminiscence.
Notably, specialists estimate that earlier than the current AI growth, about half of the world’s internet servers have been housed at Google. An unlimited community of interconnected clusters permits tens of millions of principal reminiscence models to work collectively. A Google engineer as soon as famous at a convention that, in concept, Google’s principal reminiscence might retailer your complete internet.
It’s attention-grabbing to notice that hyperlinks, together with backlinks, saved in HiveMind appear to hold considerably extra weight. For instance, hyperlinks from essential paperwork are given a lot better significance, whereas hyperlinks from URLs in TeraGoogle (HDD) could also be weighted much less or probably not thought of in any respect.
- Trace: Present your paperwork with believable and constant date values. BylineDate (date within the supply code), syntaticDate (extracted date from URL and/or title) and semanticDate (taken from the readable content material) are used, amongst others.
- Faking topicality by altering the date can actually result in downranking (demotion). The lastSignificantUpdate attribute information when the final important change was made to a doc. Fixing minor particulars or typos doesn’t have an effect on this counter.
Extra data and indicators for every DocID are saved dynamically within the repository (PerDocData). Many programs entry this later on the subject of fine-tuning relevance. It’s helpful to know that the final 20 variations of a doc are saved there (through CrawlerChangerateURLHistory).
Google has the power to judge and assess modifications over time. If you wish to utterly change the content material or subject of a doc, you’d theoretically have to create 20 intermediate variations to override the outdated content material indicators. Because of this reviving an expired area (a website that was beforehand energetic however has since been deserted or bought, maybe attributable to insolvency) doesn’t supply any rating benefit.
If a website’s Admin-C modifications and its thematic content material modifications on the similar time, a machine can simply acknowledge this at this level. Google then units all indicators to zero, and the supposedly invaluable outdated area not provides any benefits over a totally newly registered area.
QBST: Somebody is in search of ‘pencil’
When somebody enters “pencil” as a search time period in Google, QBST begins its work. The search phrase is analyzed, and if it accommodates a number of phrases, the related ones are despatched to the phrase index for retrieval.
The method of time period weighting is kind of advanced, involving programs like RankBrain, DeepRank (previously BERT) and RankEmbeddedBERT. The related phrases, corresponding to “pencil,” are then handed on to the Ascorer for additional processing.
Ascorer: The ‘inexperienced ring’ is created
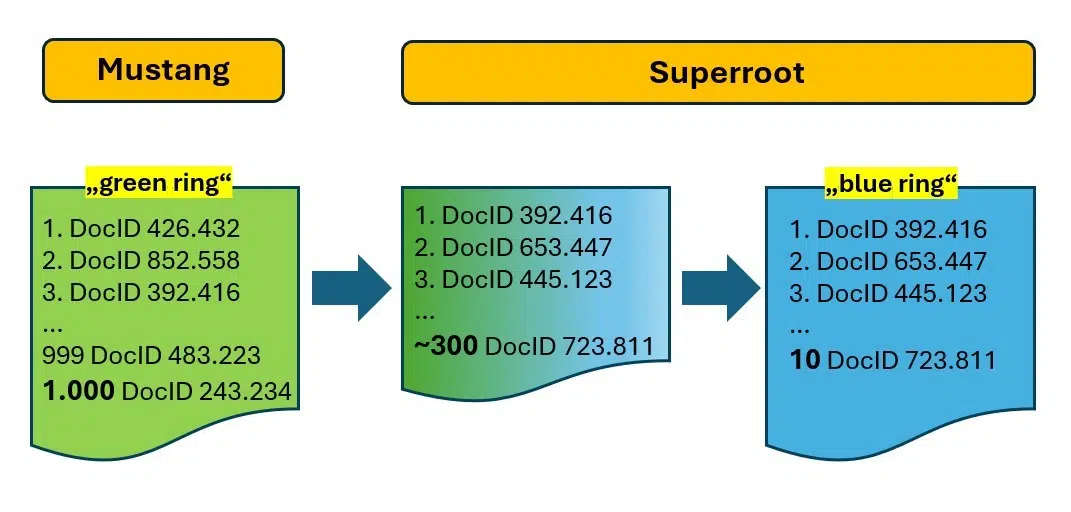
The Ascorer retrieves the highest 1,000 DocIDs for “pencil” from the inverted index, ranked by IR rating. In response to inner paperwork, this listing is known as a “inexperienced ring.” Inside the trade, it is called a posting listing.
The Ascorer is a part of a rating system referred to as Mustang, the place additional filtering happens by way of strategies corresponding to deduplication utilizing SimHash (a sort of doc fingerprint), passage evaluation, programs for recognizing unique and useful content material, and many others. The purpose is to refine the 1,000 candidates all the way down to the “10 blue hyperlinks” or the “blue ring.”
Our doc about pencils is on the posting listing, presently ranked at 132. With out extra programs, this is able to be its last place.
Superroot: Flip 1,000 into 10!
The Superroot system is answerable for re-ranking, finishing up the precision work of lowering the “inexperienced ring” (1,000 DocIDs) to the “blue ring” with solely 10 outcomes.
Twiddlers and NavBoost carry out this process. Different programs are in all probability in use right here, however their precise particulars are unclear attributable to imprecise data.
- Google Caffeine not exists on this type. Solely the identify has remained.
- Google now works with numerous micro-services that talk with one another and generate attributes for paperwork which might be used as indicators by all kinds of rating and re-ranking programs and with which the neural networks are educated to make predictions.
Filter after filter: The Twiddlers
Varied paperwork point out that a number of hundred Twiddler programs are in use. Consider a Twiddler as a plug-in just like these in WordPress.
Every Twiddler has its personal particular filter goal. They’re designed this fashion as a result of they’re comparatively straightforward to create and don’t require modifications to the advanced rating algorithms in Ascorer.
Modifying these algorithms is difficult and would contain in depth planning and programming attributable to potential negative effects. In distinction, Twiddlers function in parallel or sequentially and are unaware of the actions of different Twiddlers.
There are principally two forms of Twiddlers.
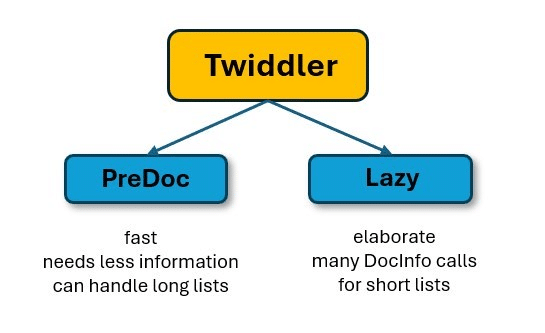
- PreDoc Twiddlers can work with your complete set of a number of hundred DocIDs as a result of they require little or no extra data.
- In distinction, Twiddlers of the “Lazy” sort require extra data, for instance, from the PerDocData database. This takes correspondingly longer and is extra advanced.
For that reason, the PreDocs first cut back the posting listing to considerably fewer entries after which begin with slower filters. This protects an infinite quantity of computing capability and time.
Some Twiddlers alter the IR rating, both positively or negatively, whereas others modify the rating place instantly. Since our doc is new to the index, a Twiddler designed to present current paperwork a greater probability of rating would possibly, as an illustration, multiply the IR rating by an element of 1.7. This adjustment might transfer our doc from the 132nd place to the 81st place.
One other Twiddler enhances range (strideCategory) within the SERPs by devaluing paperwork with comparable content material. In consequence, a number of paperwork forward of us lose their positions, permitting our pencil doc to maneuver up 12 spots to 69. Moreover, a Twiddler that limits the variety of weblog pages to 3 for particular queries boosts our rating to 61.
Our web page obtained a zero (for “Sure”) for the CommercialScore attribute. The Mustang system recognized a gross sales intention throughout evaluation. Google seemingly is aware of that searches for “pencil” are continuously adopted by refined searches like “purchase pencil,” indicating a business or transactional intent. A Twiddler designed to account for this search intent provides related outcomes and boosts our web page by 20 positions, transferring us as much as 41.
One other Twiddler comes into play, imposing a “web page three penalty” that limits pages suspected of being spam to a most rank of 31 (Web page 3). The very best place for a doc is outlined by the BadURL-demoteindex attribute, which prevents rating above this threshold. Attributes like DemoteForContent, DemoteForForwardlinks and DemoteForBacklinks are used for this goal. In consequence, three paperwork above us are demoted, permitting our web page to maneuver as much as Place 38.
Our doc might have been devalued, however to maintain issues easy, we’ll assume it stays unaffected. Let’s think about one final Twiddler that assesses how related our pencil web page is to our area based mostly on embeddings. Since our website focuses solely on writing devices, this works to our benefit and negatively impacts 24 different paperwork.
For example, think about a value comparability website with a various vary of matters however with one “good” web page about pencils. As a result of this web page’s subject differs considerably from the positioning’s total focus, it will be devalued by this Twiddler.
Attributes like siteFocusScore and siteRadius mirror this thematic distance. In consequence, our IR rating is boosted as soon as extra, and different outcomes are downgraded, transferring us as much as Place 14.
As talked about, Twiddlers serve a variety of functions. Builders can experiment with new filters, multipliers or particular place restrictions. It’s even potential to rank a end result particularly both in entrance of or behind one other end result.
One among Google’s leaked internal documents warns that sure Twiddler options ought to solely be utilized by specialists and after consulting with the core search crew.
“Should you assume you perceive how they work, belief us: you don’t. We’re undecided that we do both.”
There are additionally Twiddlers that solely create annotations and add these to the DocID on the way in which to the SERP. A picture then seems within the snippet, for instance, or the title and/or description are dynamically rewritten later.
Should you questioned through the pandemic why your nation’s nationwide well being authority (such because the Division of Well being and Human Companies within the U.S.) constantly ranked first in COVID-19 searches, it was attributable to a Twiddler that enhances official sources based mostly on language and nation utilizing queriesForWhichOfficial.
You could have little management over how Twiddler reorders your outcomes, however understanding its mechanisms will help you higher interpret rating fluctuations or “inexplicable rankings.” It’s invaluable to frequently assessment SERPs and notice the forms of outcomes.
For instance, do you constantly see solely a sure variety of discussion board or weblog posts, even with totally different search phrases? What number of outcomes are transactional, informational, or navigational? Are the identical domains repeatedly showing, or do they fluctuate with slight modifications within the search phrase?
Should you discover that just a few on-line shops are included within the outcomes, it is perhaps much less efficient to attempt rating with an identical website. As an alternative, think about specializing in extra information-oriented content material. Nonetheless, don’t leap to conclusions simply but, because the NavBoost system will probably be mentioned later.
Google’s high quality raters and RankLab
A number of thousand high quality raters work for Google worldwide to judge sure search outcomes and check new algorithms and/or filters earlier than they go “reside.”
Google explains, “Their scores don’t instantly affect rating.”
That is basically right, however these votes do have a big oblique impression on rankings.
Right here’s the way it works: Raters obtain URLs or search phrases (search outcomes) from the system and reply predetermined questions, sometimes assessed on cellular units.
For instance, they is perhaps requested, “Is it clear who wrote this content material and when? Does the creator have skilled experience on this subject?” The solutions to those questions are saved and used to coach machine studying algorithms. These algorithms analyze the traits of fine and reliable pages versus much less dependable ones.
This strategy signifies that as a substitute of counting on Google search crew members to create standards for rating, algorithms use deep studying to determine patterns based mostly on the coaching offered by human evaluators.
Let’s think about a thought experiment for instance this. Think about folks intuitively price a chunk of content material as reliable if it contains an creator’s image, full identify, and a LinkedIn biography hyperlink. Pages missing these options are perceived as much less reliable.
If a neural community is educated on varied web page options alongside these “Sure” or “No” scores, it can determine this attribute as a key issue. After a number of constructive check runs, which usually final no less than 30 days, the community would possibly begin utilizing this function as a rating sign. In consequence, pages with an creator picture, full identify, and LinkedIn hyperlink would possibly obtain a rating increase, probably by way of a Twiddler, whereas pages with out these options may very well be devalued.
Google’s official stance of not specializing in authors might align with this state of affairs. Nonetheless, leaked data reveals attributes like isAuthor and ideas corresponding to “creator fingerprinting” by way of the AuthorVectors attribute, which makes the idiolect (the person use of phrases and formulations) of an creator distinguishable or identifiable – once more through embeddings.
Raters’ evaluations are compiled into an “data satisfaction” (IS) rating. Though many raters contribute, an IS rating is just obtainable for a small fraction of URLs. For different pages with comparable patterns, this rating is extrapolated for rating functions.
Google notes, “Plenty of paperwork haven’t any clicks however could be essential.” When extrapolation isn’t potential, the system mechanically sends the doc to raters to generate a rating.
The time period “golden” is talked about in relation to high quality raters, suggesting there is perhaps a gold commonplace for sure paperwork or doc varieties. It may be inferred that aligning with the expectations of human testers might assist your doc meet this gold commonplace. Moreover, it’s seemingly that a number of Twiddlers would possibly present a big increase to DocIDs deemed “golden,” probably pushing them into the highest 10.
High quality raters are sometimes not full-time Google workers and may go by way of exterior corporations. In distinction, Google’s personal specialists function inside the RankLab, the place they conduct experiments, develop new Twiddlers and consider whether or not these or refined Twiddlers enhance end result high quality or merely filter out spam.
Confirmed and efficient Twiddlers are then built-in into the Mustang system, the place advanced, computationally intensive and interconnected algorithms are used.
Get the publication search entrepreneurs depend on.
However what do customers need? NavBoost can repair that!
Our pencil doc hasn’t totally succeeded but. Inside Superroot, one other core system, NavBoost, performs a big function in figuring out the order of search outcomes. NavBoost makes use of “slices” to handle totally different knowledge units for cellular, desktop, and native searches.
Though Google has formally denied utilizing consumer clicks for rating functions, FTC paperwork reveal an inner electronic mail instructing that the dealing with of click on knowledge should stay confidential.
This shouldn’t be held towards Google, because the denial of utilizing click on knowledge entails two key facets. Firstly, acknowledging using click on knowledge might provoke media outrage over privateness issues, portraying Google as a “knowledge octopus” monitoring our on-line exercise. Nonetheless, the intent behind utilizing click on knowledge is to acquire statistically related metrics, to not monitor particular person customers. Whereas knowledge safety advocates would possibly view this in another way, this attitude helps clarify the denial.
FTC paperwork affirm that click on knowledge is used for rating functions and continuously point out the NavBoost system on this context (54 instances within the April 18, 2023 listening to). An official listening to in 2012 additionally revealed that click on knowledge influences rankings.

It has been established that each click on habits on search outcomes and site visitors on web sites or webpages impression rankings. Google can simply consider search habits, together with searches, clicks, repeat searches and repeat clicks, instantly inside the SERPs.
There was hypothesis that Google might infer area motion knowledge from Google Analytics, main some to keep away from utilizing this method. Nonetheless, this concept has limitations.
First, Google Analytics doesn’t present entry to all transaction knowledge for a website. Extra importantly, with over 60% of individuals utilizing the Google Chrome browser (over three billion customers), Google collects knowledge on a considerable portion of internet exercise.
This makes Chrome a vital element in analyzing internet actions, as highlighted in hearings. Moreover, Core Internet Vitals indicators are formally collected by way of Chrome and aggregated into the “chromeInTotal” worth.
The unfavourable publicity related to “monitoring” is one cause for the denial, whereas one other is the priority that evaluating click on and motion knowledge might encourage spammers and tricksters to manufacture site visitors utilizing bot programs to control rankings. Whereas the denial is perhaps irritating, the underlying causes are no less than comprehensible.
- Among the metrics which might be saved embrace badClicks and goodClicks. The size of time a searcher stays on the goal web page and the knowledge on what number of different pages they view there and at what time (Chrome knowledge) are probably included on this analysis.
- A brief detour to a search end result and a fast return to the search outcomes and additional clicks on different outcomes can enhance the variety of unhealthy clicks. The search end result that had the final “good” click on in a search session is recorded because the lastLongestClick.
- The info is squashed (i.e., condensed), in order that it’s statistically normalized and fewer vulnerable to manipulation.
- If a web page, a cluster of pages or the beginning web page of a website typically has good customer metrics (Chrome knowledge), this has a constructive impact through NavBoost. By analyzing motion patterns inside a website or throughout domains, it’s even potential to find out how good the consumer steering is through the navigation.
- Since Google measures complete search periods, it’s theoretically even potential in excessive circumstances to acknowledge {that a} utterly totally different doc is taken into account appropriate for a search question. If a searcher leaves the area that they clicked on within the search end result inside a search and goes to a different area (as a result of it could even have been linked from there) and stays there because the recognizable finish of the search, this “finish” doc may very well be flushed to the entrance through NavBoost sooner or later, offered it’s obtainable within the choice ring set. Nonetheless, this is able to require a robust statistically related sign from many searchers.
Let’s first study clicks in search outcomes. Every rating place within the SERPs has a mean anticipated click-through price (CTR), serving as a efficiency benchmark. For instance, in line with an evaluation by Johannes Beus introduced at this yr’s CAMPIXX in Berlin, the natural Place 1 receives a mean of 26.2% of clicks, whereas Place 2 will get 15.5%.
If a snippet’s precise CTR considerably falls wanting the anticipated price, the NavBoost system registers this discrepancy and adjusts the rating of the DocIDs accordingly. If a end result traditionally generates considerably extra or fewer clicks than anticipated, NavBoost will transfer the doc up or down within the rankings as wanted (see Determine 6).
This strategy is sensible as a result of clicks basically signify a vote from customers on the relevance of a end result based mostly on the title, description and area. This idea is even detailed in official paperwork, as illustrated in Determine 7.
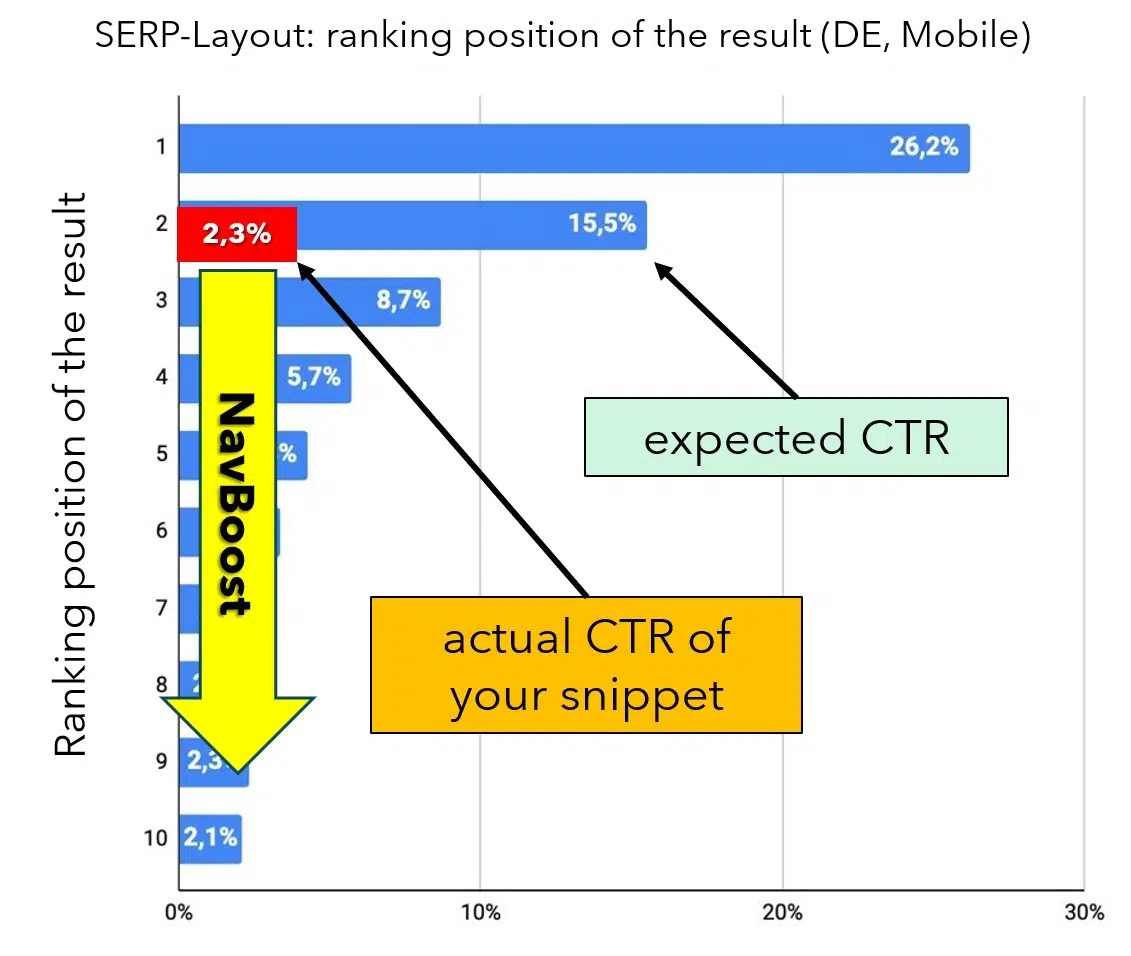
Since our pencil doc remains to be new, there aren’t any obtainable CTR values but. It’s unclear whether or not CTR deviations are ignored for paperwork with no knowledge, however this appears seemingly, because the purpose is to include consumer suggestions. Alternatively, the CTR would possibly initially be estimated based mostly on different values, just like how the standard issue is dealt with in Google Advertisements.
- website positioning specialists and knowledge analysts have lengthy reported that they’ve seen the next phenomenon when comprehensively monitoring their very own click-through charges: If a doc for a search question newly seems within the high 10 and the CTR falls considerably wanting expectations, you’ll be able to observe a drop in rating inside a couple of days (relying on the search quantity).
- Conversely, the rating typically rises if the CTR is considerably greater in relation to the rank. You solely have a short while to react and alter the snippet if the CTR is poor (normally by optimizing the title and outline) in order that extra clicks are collected. In any other case, the place deteriorates and is subsequently not really easy to regain. Checks are regarded as behind this phenomenon. If a doc proves itself, it could possibly keep. If searchers don’t prefer it, it disappears once more. Whether or not that is truly associated to NavBoost is neither clear nor conclusively provable.
Based mostly on the leaked data, it seems that Google makes use of in depth knowledge from a web page’s “surroundings” to estimate indicators for brand spanking new, unknown pages.
For example, NearestSeedversion means that the PageRank of the house web page HomePageRank_NS is transferred to new pages till they develop their very own PageRank. Moreover, pnavClicks appears to be used to estimate and assign the likelihood of clicks by way of navigation.
Calculating and updating PageRank is time-consuming and computationally intensive, which is why the PageRank_NS metric is probably going used as a substitute. “NS” stands for “nearest seed,” that means {that a} set of associated pages shares a PageRank worth, which is briefly or completely utilized to new pages.
It’s possible that values from neighboring pages are additionally used for different crucial indicators, serving to new pages climb the rankings regardless of missing important site visitors or backlinks. Many indicators should not attributed in real-time however could contain a notable delay.
- Google itself set instance of freshness throughout a listening to. For instance, in case you seek for “Stanley Cup,” the search outcomes sometimes function the well-known mug. Nonetheless, when the Stanley Cup ice hockey video games are actively going down, NavBoost adjusts the outcomes to prioritize details about the video games, reflecting modifications in search and click on habits.
- Freshness doesn’t discuss with new (i.e., “contemporary”) paperwork however to modifications in search habits. In response to Google, there are over a billion (that’s not a typo) new behaviors within the SERPs day by day! So each search and each click on contributes to Google’s studying. The belief that Google is aware of the whole lot about seasonality might be not right. Google acknowledges fine-grained modifications in search intentions and continually adapts the system – which creates the phantasm that Google truly “understands” what searchers need.
The clicking metrics for paperwork are apparently saved and evaluated over a interval of 13 months (one month overlap within the yr for comparisons with the earlier yr), in line with the newest findings.
Since our hypothetical area has sturdy customer metrics and substantial direct site visitors from promoting, as a widely known model (which is a constructive sign), our new pencil doc advantages from the favorable indicators of older, profitable pages.
In consequence, NavBoost elevates our rating from 14th to fifth place, putting us within the “blue ring” or high 10. This high 10 listing, together with our doc, is then forwarded to the Google Internet Server together with the opposite 9 natural outcomes.
- Opposite to expectations, Google doesn’t truly ship many personalised search outcomes. Checks have in all probability proven that modeling consumer habits and making modifications to it delivers higher outcomes than evaluating the private preferences of particular person customers.
- That is outstanding. The prediction through neural networks is now higher suited to us than our personal browsing and clicking historical past. Nonetheless, particular person preferences, corresponding to a choice for video content material, are nonetheless included within the private outcomes.
The GWS: The place the whole lot involves an finish and a brand new starting
The Google Internet Server (GWS) is answerable for assembling and delivering the search outcomes web page (SERP). This contains 10 blue hyperlinks, together with advertisements, photos, Google Maps views, “Folks additionally ask” sections and different parts.
The Tangram system handles geometric house optimization, calculating how a lot house every aspect requires and what number of outcomes match into the obtainable “containers.” The Glue system then arranges these parts of their correct locations.
Our pencil doc, presently in fifth place, is a part of the natural outcomes. Nonetheless, the CookBook system can intervene on the final second. This technique contains FreshnessNode, InstantGlue (reacts in durations of 24 hours with a delay of round 10 minutes) and InstantNavBoost. These elements generate extra indicators associated to topicality and may alter rankings within the last moments earlier than the web page is displayed.
Let’s say a German TV program about 250 years of Faber-Castell and the myths surrounding the phrase “pencil” begins to air. Inside minutes, 1000’s of viewers seize their smartphones or tablets to go looking on-line. This can be a typical state of affairs. FreshnessNode detects the surge in searches for “pencil” and, noting that customers are in search of data somewhat than making purchases, adjusts the rankings accordingly.
On this distinctive scenario, InstantNavBoost removes all transactional outcomes and replaces them with informational ones in actual time. InstantGlue then updates the “blue ring,” inflicting our beforehand sales-oriented doc to drop out of the highest rankings and get replaced by extra related outcomes.
Unlucky as it could be, this hypothetical finish to our rating journey illustrates an essential level: reaching a excessive rating isn’t solely about having a terrific doc or implementing the precise website positioning measures with high-quality content material.
Rankings could be influenced by a wide range of elements, together with modifications in search habits, new indicators for different paperwork and evolving circumstances. Due to this fact, it’s essential to acknowledge that having a wonderful doc and doing job with website positioning is only one a part of a broader and extra dynamic rating panorama.
The method of compiling search outcomes is extraordinarily advanced, influenced by 1000’s of indicators. With quite a few checks performed reside by SearchLab utilizing Twiddler, even backlinks to your paperwork could be affected.
These paperwork is perhaps moved from HiveMind to much less crucial ranges, corresponding to SSDs and even TeraGoogle, which might weaken or remove their impression on rankings. This could shift rating scales even when nothing has modified with your individual doc.
Google’s John Mueller has emphasised {that a} drop in rating typically doesn’t imply you’ve carried out something unsuitable. Adjustments in consumer habits or different elements can alter how outcomes carry out.
For example, if searchers begin preferring extra detailed data and shorter texts over time, NavBoost will mechanically alter rankings accordingly. Nonetheless, the IR rating within the Alexandria system or Ascorer stays unchanged.
One key takeaway is that website positioning should be understood in a broader context. Optimizing titles or content material gained’t be efficient if a doc and its search intent don’t align.
The impression of Twiddlers and NavBoost on rankings can typically outweigh conventional on-page, on-site or off-site optimizations. If these programs restrict a doc’s visibility, extra on-page enhancements may have minimal impact.
Nonetheless, our journey doesn’t finish on a low notice. The impression of the TV program about pencils is momentary. As soon as the search surge subsides, FreshnessNode will not have an effect on our rating, and we’ll settle again at fifth place.
As we restart the cycle of amassing click on knowledge, a CTR of round 4% is predicted for Place 5 (based mostly on Johannes Beus from SISTRIX). If we are able to preserve this CTR, we are able to anticipate staying within the high ten. All will probably be effectively.
Key website positioning takeaways
- Diversify site visitors sources: Make sure you obtain site visitors from varied sources, not simply search engines like google. Site visitors from much less apparent channels, like social media platforms, can be invaluable. Even when Google’s crawler can’t entry sure pages, Google can nonetheless monitor what number of guests come to your website by way of platforms like Chrome or direct URLs.
- Construct model and area consciousness: At all times work on strengthening your model or area identify recognition. The extra acquainted persons are along with your identify, the extra seemingly they’re to click on in your website in search outcomes. Rating for a lot of long-tail key phrases may also increase your area’s visibility. Leaks recommend that “website authority” is a rating sign, so constructing your model’s popularity will help enhance your search rankings.
- Perceive search intent: To raised meet your guests’ wants, attempt to perceive their search intent and journey. Use instruments like Semrush or SimilarWeb to see the place your guests come from and the place they go after visiting your website. Analyze these domains – do they provide data that your touchdown pages lack? Step by step add this lacking content material to develop into the “last vacation spot” in your guests’ search journey. Bear in mind, Google tracks associated search periods and is aware of exactly what searchers are in search of and the place they’ve been looking.
- Optimize your titles and descriptions to enhance CTR: Begin by reviewing your present CTR and making changes to reinforce click on enchantment. Capitalizing a couple of essential phrases will help them stand out visually, probably boosting CTR; check this strategy to see if it really works for you. The title performs a crucial function in figuring out whether or not your web page ranks effectively for a search term, so optimizing it must be a high precedence.
- Consider hidden content material: Should you use accordions to “conceal” essential content material that requires a click on to disclose, verify if these pages have a higher-than-average bounce price. When searchers can’t instantly see they’re in the precise place and have to click on a number of instances, the chance of unfavourable click on indicators will increase.
- Take away underperforming pages: Pages that no one visits (internet analytics) or that don’t obtain rating over longer durations of time must be eliminated if needed. Dangerous indicators are additionally handed on to neighboring pages! Should you publish a brand new doc in a “unhealthy” web page cluster, the brand new web page has few probabilities. “deltaPageQuality” apparently truly measures the qualitative distinction between particular person paperwork in a website or cluster.
- Improve web page construction: A transparent web page construction, straightforward navigation and a robust first impression are important for reaching high rankings, typically because of NavBoost.
- Maximize engagement: The longer guests keep in your website, the higher the indicators your area sends, which advantages your entire subpages. Intention to be the ultimate vacation spot by offering all the knowledge they want so guests gained’t have to go looking elsewhere.
- Increase present content material somewhat than continually creating new ones: Updating and enhancing your present content material could be more practical. ContentEffortScore measures the hassle put into making a doc, with elements like high-quality photos, movies, instruments and distinctive content material all contributing to this essential sign.
- Align your headings with the content material they introduce: Be sure that (intermediate) headings precisely mirror the textual content blocks that observe. Thematic evaluation, utilizing methods like embeddings (textual content vectorization), is more practical at figuring out whether or not headings and content material match accurately in comparison with purely lexical strategies.
- Make the most of internet analytics: Instruments like Google Analytics enables you to monitor customer engagement successfully and determine and deal with any gaps. Pay specific consideration to the bounce price of your touchdown pages. If it’s too excessive, examine potential causes and take corrective actions. Bear in mind, Google can entry this knowledge by way of the Chrome browser.
- Goal much less aggressive key phrases: You can too concentrate on rating effectively for much less aggressive key phrases first and thus extra simply construct up constructive consumer indicators.
- Domesticate high quality backlinks: Give attention to hyperlinks from current or high-traffic pages saved in HiveMind, as these present extra invaluable indicators. Hyperlinks from pages with little site visitors or engagement are much less efficient. Moreover, backlinks from pages inside the similar nation and people with thematic relevance to your content material are extra helpful. Bear in mind that “poisonous” backlinks, which negatively impression your rating, do exist and must be prevented.
- Take note of the context surrounding hyperlinks: The textual content earlier than and after a hyperlink, not simply the anchor textual content itself, are thought of for rating. Be certain that the textual content naturally flows across the hyperlink. Keep away from utilizing generic phrases like “click on right here,” which has been ineffective for over twenty years.
- Pay attention to the Disavow device’s limitations: The Disavow device, used to invalidate unhealthy hyperlinks, isn’t talked about within the leak in any respect. Evidently algorithms don’t think about it, and it serves primarily a documentary goal for spam fighters.
- Contemplate creator experience: Should you use creator references, guarantee they’re additionally acknowledged on different web sites and display related experience. Having fewer however extremely certified authors is best than having many much less credible ones. In response to a patent, Google can assess content material based mostly on the creator’s experience, distinguishing between specialists and laypeople.
- Create unique, useful, complete and well-structured content material: That is particularly essential for key pages. Show your real experience on the subject and, if potential, present proof of it. Whereas it’s straightforward to have somebody write content material simply to have one thing on the web page, setting excessive rating expectations with out actual high quality and experience is probably not lifelike.
A model of this text was initially revealed in German in August 2024 in Web site Boosting, Challenge 87.
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search neighborhood. Our contributors work beneath the oversight of the editorial staff and contributions are checked for high quality and relevance to our readers. The opinions they categorical are their very own.