
A massive Google Search internal ranking documentation leak has despatched shockwaves by way of the website positioning group. The leak, which uncovered over 14,000 potential rating options, supplies an unprecedented look beneath the hood of Google’s intently guarded search rankings system.
A person named Erfan Azimi shared a Google API doc leak with SparkToro’s Rand Fishkin, who, in flip, introduced in Michael King of iPullRank, to get his assist in distributing this story.
The leaked information originated from a Google API doc commit titled “yoshi-code-bot /elixer-google-api,” which suggests this was not a hack or a whistle-blower.
SEOs sometimes occupy three camps:
- All the pieces Google tells SEOs is true and we must always comply with these phrases as our scripture (I name these individuals the Google Cheerleaders).
- Google is a liar, and you’ll’t belief something Google says. (I consider them as blackhat SEOs.)
- Google generally tells the reality, however you have to take a look at every little thing to see if you will discover it. (I self-identify with this camp and I’ll name this “Invoice Slawski rationalism” since he was the one who satisfied me of this view).
I believe many individuals shall be altering their camp after this leak.
You’ll find all of the information here, however it is best to know that over 14,000 potential rating indicators/options exist, and it’ll take you a complete day (or, in my case, night time) to dig by way of every little thing.
I’ve learn by way of your complete factor and distilled it right into a 40-page PDF that I’m now changing right into a abstract for Search Engine Land.
Whereas I present my ideas and opinions, I’m additionally sharing the names of the particular rating options so you’ll be able to search the database by yourself. I encourage everybody to make their very own conclusions.
Key factors from Google Search doc leak
- Nearest seed has modified PageRank (now deprecated). The algorithm known as pageRank_NS and it’s related to doc understanding.
- Google has seven several types of PageRank talked about, one among which is the well-known ToolBarPageRank.
- Google has a particular technique of figuring out the next enterprise fashions: information, YMYL, private blogs (small blogs), ecommerce and video websites. It’s unclear why Google is particularly filtering for private blogs.
- A very powerful parts of Google’s algorithm look like navBoost, NSR and chardScores.
- Google makes use of a site-wide authority metric and some site-wide authority indicators, together with site visitors from Chrome browsers.
- Google makes use of web page embeddings, website embeddings, website focus and website radius in its scoring perform.
- Google measures unhealthy clicks, good clicks, clicks, final longest clicks and site-wide impressions.
Why is Google particularly filtering for private blogs / small websites? Why did Google publicly say on many events that they don’t have a site or website authority measurement?
Why did Google lie about their use of click on knowledge? Why does Google have seven varieties of PageRank?
I don’t have the solutions to those questions, however they’re mysteries the website positioning group would love to know.
Issues that stand out: Favourite discoveries
Google has one thing referred to as pageQuality (PQ). One of the vital fascinating elements of this measurement is that Google is utilizing an LLM to estimate “effort” for article pages. This worth sounds useful for Google in figuring out whether or not a web page could be replicated simply.
Takeaway: Instruments, photos, movies, distinctive data and depth of knowledge stand out as methods to attain excessive on “effort” calculations. Coincidentally, these items have additionally been confirmed to fulfill customers.
Subject borders and subject authority look like actual
Topical authority is an idea based mostly on Google’s patent analysis. In the event you’ve learn the patents, you’ll see that lots of the insights SEOs have gleaned from patents are supported by this leak.
Within the algo leak, we see that siteFocusScore, siteRadius, siteEmbeddings and pageEmbeddings are used for rating.
What are they?
- siteFocusScore denotes how a lot a website is targeted on a particular subject.
- siteRadius measures how far web page embeddings deviate from the location embedding. In plain speech, Google creates a topical identification in your web site, and each web page is measured in opposition to that identification.
- siteEmbeddings are compressed website/web page embeddings.
Why is that this fascinating?
- If you know the way embeddings work, you’ll be able to optimize your pages to ship content material in a approach that’s higher for Google’s understanding.
- Subject focus is instantly referred to as out right here. We don’t know why subject focus is talked about, however we all know {that a} quantity worth is given to a web site based mostly on the location’s subject rating.
- Deviation from the subject is measured, which signifies that the idea of topical borders and contextual bridging has some potential assist outdoors of patents.
- It might seem that topical identification and topical measurements normally are a spotlight for Google.
Keep in mind after I mentioned PageRank is deprecated? I imagine nearest seed (NS) can apply within the realm of topical authority.
NS focuses on a localized subset of the community across the seed nodes. Proximity and relevance are key focus areas. It may be customized based mostly on consumer curiosity, making certain pages inside a subject cluster are thought-about extra related with out utilizing the broad web-wide PageRank formulation.
One other approach of approaching that is to use NS and PQ (web page high quality) collectively.
Through the use of PQ scores as a mechanism for aiding the seed willpower, you possibly can enhance the unique PageRank algorithm additional.
On the alternative finish, we may apply this to lowQuality (one other rating from the doc). If a low-quality web page hyperlinks to different pages, then the low high quality may taint the opposite pages by seed affiliation.
A seed isn’t essentially a top quality node. It could possibly be a poor-quality node.
After we apply site2Vec and the data of siteEmbeddings, I feel the speculation holds water.
If we lengthen this past a single web site, I think about variants of Panda may work on this approach. All that Google must do is start with a low-quality cluster and extrapolate sample insights.
What if NS may work along with OnsiteProminence (rating worth from the leak)?
On this state of affairs, nearest seed may establish how intently sure pages relate to high-traffic pages.
Picture high quality
ImageQualityClickSignals signifies that picture high quality measured by click on (usefulness, presentation, appealingness, engagingness). These indicators are thought-about Search CPS Private knowledge.
No thought whether or not appealingness or engagingness are phrases – nevertheless it’s tremendous fascinating!
Host NSR
I imagine NSR is an acronym for Normalized Web site Rank.
Host NSR is website rank computed for host-level (web site) sitechunks. This worth encodes nsr, site_pr and new_nsr. Vital to notice that nsr_data_proto appears to be the latest model of this however not a lot information could be discovered.
In essence, a sitechunk is taking chunks of your area and also you get website rank by measuring these chunks. This is sensible as a result of we already know Google does this on a page-by-page, paragraph and topical foundation.
It virtually looks as if a chunking system designed to ballot random high quality metric scores rooted in aggregates. It’s kinda like a pop quiz (tough analogy).
NavBoost
I’ll talk about this extra, nevertheless it is among the rating items most talked about within the leak. NavBoost is a re-ranking based mostly on click on logs of consumer habits. Google has denied this many instances, however a recent court case compelled them to disclose that they rely fairly closely on click on knowledge.
Essentially the most fascinating half (which mustn’t come as a shock) is that Chrome knowledge is particularly used. I think about this extends to Android gadgets as properly.
This could be extra fascinating if we introduced within the patent for the site quality score. Hyperlinks have a ratio with clicks, and we see fairly clearly within the leak docs that subjects, hyperlinks and clicks have a relationship.
Whereas I can’t make conclusions right here, I do know what Google has shared concerning the Panda algorithm and what the patents say. I additionally know that Panda, Child Panda and Child Panda V2 are talked about within the leak.
If I needed to guess, I’d say that Google makes use of the referring area and click on ratio to find out rating demotions.
HostAge
Nothing a couple of web site’s age is taken into account in rating scores, however the hostAge is talked about concerning a sandbox. The information is utilized in Twiddler to sandbox contemporary spam throughout serving time.
I contemplate this an fascinating discovering as a result of many SEOs argue concerning the sandbox and plenty of argue concerning the significance of area age.
So far as the leak is worried, the sandbox is for spam and area age doesn’t matter.
ScaledIndyRank. Independence rank. Nothing else is talked about, and the ExptIndyRank3 is taken into account experimental. If I needed to guess, this has one thing to do with data achieve on a sitewide degree (unique content material).
Be aware: It is very important do not forget that we don’t know to what extent Google makes use of these scoring components. Nearly all of the algorithm is a secret. My ideas are based mostly on what I’m seeing on this leak and what I’ve learn by finding out three years of Google patents.
Find out how to take away Google’s reminiscence of an previous model of a doc
That is maybe a little bit of conjecture, however the logic is sound. In response to the leak, Google retains a report of each model of a webpage. This implies Google has an inner net archive of kinds (Google’s personal model of the Wayback Machine).
The nuance is that Google solely makes use of the final 20 variations of a doc. In the event you replace a web page, look ahead to a crawl and repeat the method 20 instances, you’ll successfully push out sure variations of the web page.
This is perhaps helpful data, contemplating that the historic variations are related to varied weights and scores.
Keep in mind that the documentation has two types of replace historical past: important replace and replace. It’s unclear whether or not important updates are required for this type of model reminiscence tom-foolery.
Google Search rating system
Whereas it’s conjecture, one of the fascinating issues I discovered was the time period weight (literal dimension).
This could point out that bolding your phrases or the scale of the phrases, normally, has some type of impression on doc scores.
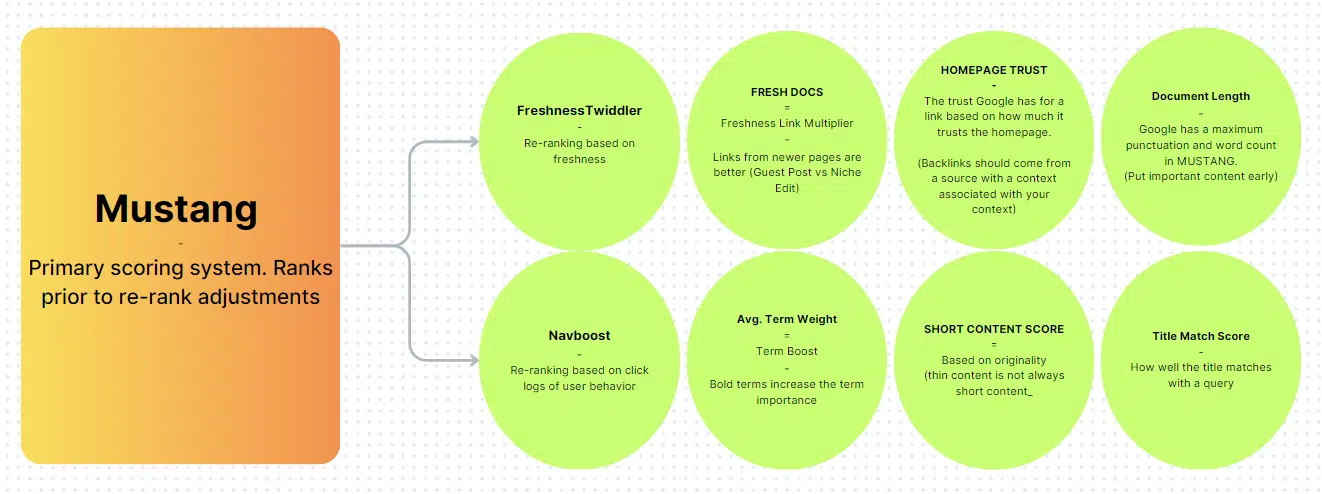
Index storage mechanisms
- Flash drives: Used for a very powerful and often up to date content material.
- Stable state drives: Used for much less essential content material.
- Customary arduous drives: Used for irregularly up to date content material.
Curiously, the usual arduous drive is used for irregularly up to date content material.
Get the every day e-newsletter search entrepreneurs depend on.
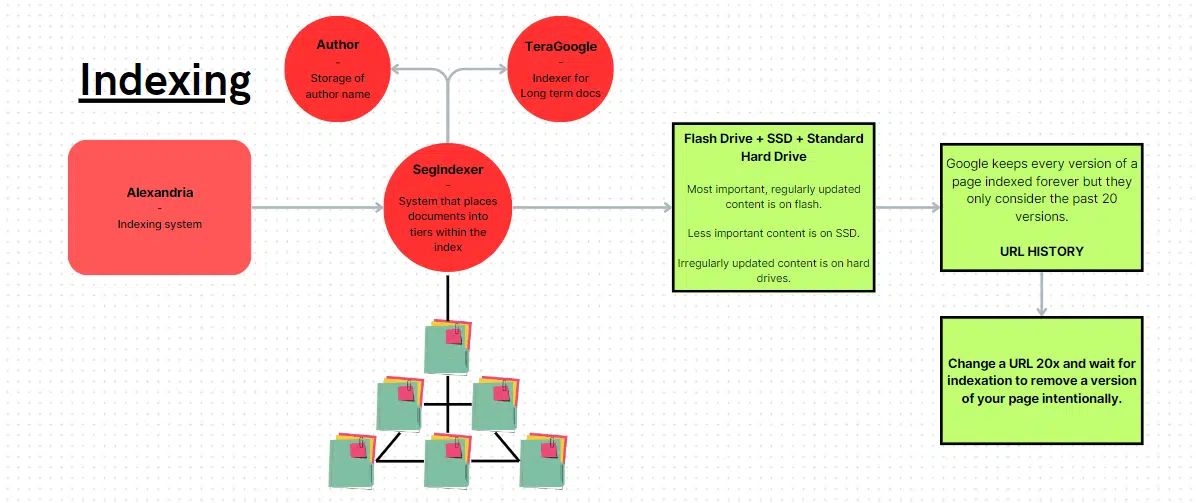
Google’s indexer now has a reputation: Alexandria
Go determine. Google would title the biggest index of knowledge after essentially the most well-known library. Let’s hope the identical destiny doesn’t befall Google.
Two different indexers are prevalent within the documentation: SegIndexer and TeraGoogle.
- SegIndexer is a system that locations paperwork into tiers inside its index.
- TeraGoogle is long-term reminiscence storage.
Did we simply affirm seed websites or sitewide authority?
The part titled “GoogleApi.ContentWarehouse.V1.Mannequin.QualityNsrNsrData” mentions an element named isElectionAuthority. The leak says, “Bit to find out whether or not the location has the election authority sign.”
That is fascinating as a result of it is perhaps what individuals discuss with as “seed websites.” It may be topical authorities or web sites with a PageRank of 9/10 (Be aware: toolbarPageRank is referenced within the leak).
It’s essential to notice that nsrIsElectionAuthority (a barely totally different issue) is taken into account deprecated, so who is aware of how we must always interpret this.
This particular part is among the most densely packed sections in your complete leak.
Brief content material can rank
Suprise, suprise! Brief content material doesn’t equal skinny content material. I’ve been making an attempt to show this with my cocktail recipe pages, and this leak confirms my suspicion.
Curiously sufficient, brief content material has a unique scoring system utilized to it (not completely distinctive however totally different to an extent).
Recent hyperlinks appear to trump current hyperlinks
This one was a little bit of a shock, and I could possibly be misunderstanding issues right here. In response to freshdocs, a hyperlink worth multiplier, hyperlinks from newer webpages are higher than hyperlinks inserted into older content material.
Clearly, we should nonetheless incorporate our data of a high-value web page (talked about all through this presentation).
Nonetheless, I had this one improper in my thoughts. I figured the age could be a great factor, however in actuality, it isn’t actually the age that offers a distinct segment edit worth, it’s the site visitors or inner hyperlinks to the web page (should you go the area of interest edit route).
This doesn’t imply area of interest edits are ineffective. It merely signifies that hyperlinks from newer pages seem to get an unknown worth multiplier.
High quality NsrNsrData
Here’s a listing of some scoring components that stood out most from the NsrNsrData doc.
- titlematchScore: A sitewide title match rating that could be a sign that tells how properly titles match consumer queries. (I by no means even thought-about {that a} site-wide title rating could possibly be used.)
- site2vecEmbedding: Like word2vec, this can be a sitewide vector, and it’s fascinating to see it included right here.
- pnavClicks: I’m undecided what pnav is, however I’d assume this refers to navigational data derived from consumer click on knowledge.
- chromeInTotal: Web site-wide Chrome views. For an algorithm constructed on particular pages, Google undoubtedly likes to make use of site-wide indicators.
- chardVariance and chardScoreVariance: I imagine Google is making use of site-level chard scores, which predict website/web page high quality based mostly in your content material. Google measures variances in any approach you’ll be able to think about, so consistency is essential.
NSR and Qstar
It looks as if website authority and a bunch of NSR-related scores are all utilized in Qstar. My finest guess is that Qstar is the combination measurement of a web site’s scores. It probably consists of authority as simply a kind of combination values.
Scoring within the absence of measurement
nsrdataFromFallbackPatternKey. If NSR knowledge has not been computed for a piece, then knowledge comes from a mean of different chunks from the web site. Mainly, you have got chunks of your website which have values related to them and these values are averaged and utilized to the unknown doc.
Google is making scores based mostly on subjects, inner hyperlinks, referring domains, ratios, clicks and all kinds of different issues. If normalized website rank hasn’t been computed for a piece (Google used chunks of your web site and pages for scoring functions), the present scores related to different chunks shall be averaged and utilized to the unscored chunk.
I don’t suppose you’ll be able to optimize for this, however one factor has been made abundantly clear:
You have to actually deal with constant high quality, otherwise you’ll find yourself hurting your website positioning scores throughout the board by reducing your rating common or topicality.
Demotions to be careful for
A lot of the content material from the leak centered on demotions that Google makes use of. I discover this as useful (perhaps much more useful) because the optimistic scoring components.
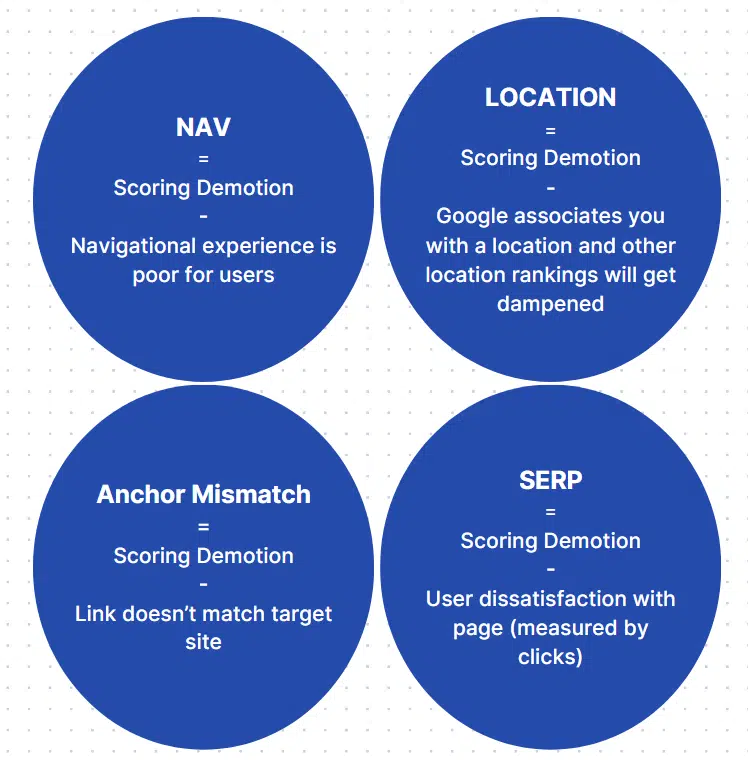
Key factors:
- Poor navigational expertise hurts your rating.
- Location identification hurts your scores for pages making an attempt to rank for a location not essentially linked to your location identification.
- Hyperlinks that don’t match the goal website will harm your rating.
- Consumer click on dissatisfaction hurts your rating.
It’s essential to notice that click on satisfaction scores aren’t based mostly on dwell time. In the event you proceed trying to find data NavBoost deems to be the identical, you’ll get the scoring demotion.
A novel a part of NavBoost is its position in bundling queries based mostly on interpreted that means.
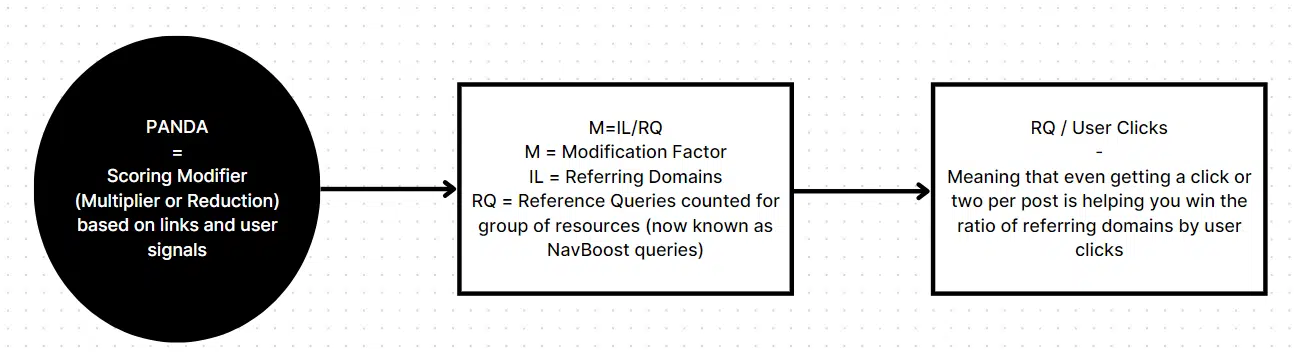
Spam
- gibberishScores are talked about. This refers to spun content material, filler AI content material and straight nonsense. Some individuals say Google can’t perceive content material. Heck, Google says they don’t perceive the content material. I’d say Google can fake to know on the very least, and it certain mentions rather a lot about content material high quality for an algorithm with no means to “perceive.”
- phraseAnchorSpamPenalty: Mixed penalty for anchor demotion. This isn’t a hyperlink demotion or authority demotion. It is a demotion of the rating particularly tied to the anchor. Anchors have fairly a little bit of significance.
- trendSpam: For my part, that is CTR manipulation-centered. “Depend of matching development spam queries.”
- keywordStuffingScore: Prefer it sounds, this can be a rating of key phrase stuffing spam.
- spamBrainTotalDocSpamScore: Spam rating recognized by spam mind going from 0 to 1.
- spamRank: Measures the probability {that a} doc hyperlinks to recognized spammers. Worth is 0 and 65535 (idk why it solely has two values).
- spamWordScore: Apparently, sure phrases are spammy. I primarily discovered this rating regarding anchors.
Anchor textual content
How is nobody speaking about this one? A complete web page devoted to anchor textual content statement, measurement, calculation and evaluation.
- Over what number of days 80% of those phrases had been found” is an fascinating one.
- Spam phrase fraction of all anchors of the doc (probably hyperlink farm detection tactic – promote much less hyperlinks per web page).
- The common every day fee of spam anchor discovery.
- What number of spam phrases are discovered within the anchors amongst distinctive domains.
- Complete variety of trusted sources for this URL.
- The variety of trusted anchors with anchor textual content matching spam phrases.
- Trusted examples are merely a listing of trusted sources.
On the finish of all of it, you get spam likelihood and a spam penalty.
Right here’s an enormous spoonful of unfairness, and it doesn’t shock any website positioning veterans.
trustedTarget is a metric related to spam anchors, and it says “True if this URL is on trusted supply.”
Whenever you grow to be “trusted” you will get away with extra, and should you’ve investigated these “trusted sources,” you’ll see that they get away with fairly a bit.
On a optimistic observe, Google has a Trawler coverage that primarily appends “spam” to recognized spammers, and most crawls auto-reject spammers’ IPs.
9 items of actionable recommendation to think about
- You need to put money into a well-designed website with intuitive structure so you’ll be able to optimize for NavBoost.
- When you’ve got a website the place website positioning is essential, it is best to take away / block pages that aren’t topically related. You may contextually bridge two subjects to strengthen topical connections. Nonetheless, you should first set up your goal subject and guarantee every web page scores properly by optimizing for every little thing I’m sharing on the backside of this doc.
- As a result of embeddings are used on a page-by-page and site-wide foundation, we should optimize our headings round queries and make the paragraphs beneath the headings reply these queries clearly and succinctly.
- Clicks and impressions are aggregated and utilized on a topical foundation, so it is best to write extra content material that may earn extra impressions and clicks. Even should you’re solely chipping away on the impression and click on rely, should you present a great expertise and are constant together with your subject growth, you’ll begin profitable, in response to the leaked docs.
- Irregularly up to date content material has the bottom storage precedence for Google and is certainly not displaying up for freshness. It is extremely essential to replace your content material. Search methods to replace the content material by including distinctive information, new photos, and video content material. Intention to kill two birds with one stone by scoring excessive on the “effort calculations” metric.
- Whereas it’s tough to keep up high-quality content material and publishing frequency, there’s a reward. Google is making use of site-level chard scores, which predict website/web page high quality based mostly in your content material. Google measures variances in any approach you’ll be able to think about, so consistency is essential.
- Impressions for your complete web site are a part of the standard NSR knowledge. This implies it is best to actually worth the impression development as it’s a good signal.
- Entities are essential. Salience scores for entities and prime entity identification are talked about.
- Take away poorly performing pages. If consumer metrics are unhealthy, no hyperlinks level to the web page and the web page has had loads of alternative to thrive, then that web page needs to be eradicated. Web site-wide scores and scoring averages are talked about all through the leaked docs, and it’s simply as worthwhile to delete the weakest hyperlinks as it’s to optimize your new article (with some caveats).
The unified idea of rating: Solely utilizing leaked components
This isn’t an ideal depiction of Google’s algorithm, nevertheless it’s a enjoyable try and consolidate the components and specific the leak right into a mathematical formulation (minus the exact weights).
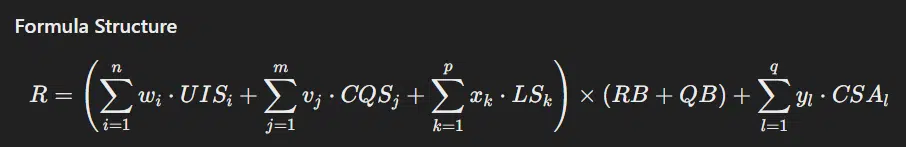
Definitions and metrics
R: General rating rating
UIS (Consumer Interplay Scores)

- UgcScore: Rating based mostly on user-generated content material engagement
- TitleMatchScore: Rating for title relevance and match with consumer question
- ChromeInTotal: Complete interactions tracked through Chrome knowledge
- SiteImpressions: Complete impressions for the location
- TopicImpressions: Impressions on topic-specific pages
- SiteClicks: Click on-through fee for the location
- TopicClicks: Click on-through fee for topic-specific pages
CQS (Content material High quality Scores)
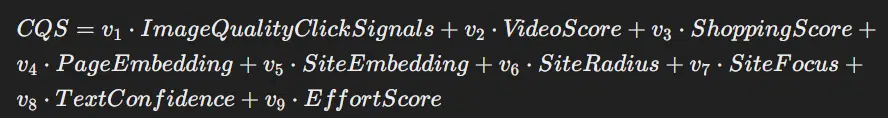
- ImageQualityClickSignals: High quality indicators from picture clicks
- VideoScore: Rating based mostly on video high quality and engagement
- ShoppingScore: Rating for shopping-related content material
- PageEmbedding: Semantic embedding of web page content material
- SiteEmbedding: Semantic embedding of website content material
- SiteRadius: Measure of deviation inside the website embedding
- SiteFocus: Metric indicating subject focus
- TextConfidence: Confidence within the textual content’s relevance and high quality
- EffortScore: Effort and high quality within the content material creation
LS (Hyperlink Scores)
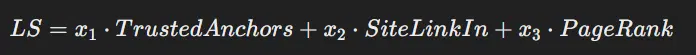
- TrustedAnchors: High quality and trustworthiness of inbound hyperlinks
- SiteLinkIn: Common worth of incoming hyperlinks
- PageRank: PageRank rating contemplating varied components (0,1,2, ToolBar, NR)
RB (Relevance Increase): Relevance increase based mostly on question and content material match

- TopicEmbedding: Relevance over time worth
- QnA (High quality earlier than Adjustment): Baseline high quality measure
- STS (Semantic Textual content Scores): Mixture rating based mostly on textual content understanding, salience and entities
QB (High quality Increase): Increase based mostly on total content material and website high quality

- SAS (Web site Authority Rating): Sum of scores regarding belief, reliability and hyperlink authority
- EFTS (Effort Rating): Web page effort incorporating textual content, multimedia and feedback
- FS (Freshness Rating): Replace tracker and unique put up date tracker
CSA (Content material-Particular Changes): Changes based mostly on particular content material options on SERP and on web page
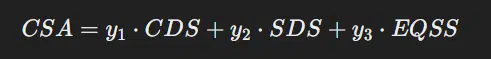
- CDS (Chrome Knowledge Rating): Rating based mostly on Chrome knowledge, specializing in impressions and clicks throughout the location
- SDS (Serp Demotion Rating): Discount based mostly on SERP expertise measurement rating
- EQSS (Experimental Q Star Rating): Catch-all rating for experimental variables examined every day
Full formulation
R=((w1⋅UgcScore+w2⋅TitleMatchScore+w3⋅ChromeInTotal+w4⋅SiteImpressions+w5⋅TopicImpressions+w6⋅SiteClicks+w7⋅TopicClicks)+(v1⋅ImageQualityClickSignals+v2⋅VideoScore+v3⋅ShoppingScore+v4⋅PageEmbedding+v5⋅SiteEmbedding+v6⋅SiteRadius+v7⋅SiteFocus+v8⋅TextConfidence+v9⋅EffortScore)+(x1⋅TrustedAnchors+x2⋅SiteLinkIn+x3⋅PageRank))×(TopicEmbedding+QnA+STS+SAS+EFTS+FS)+(y1⋅CDS+y2⋅SDS+y3⋅EQSS)
Generalized scoring overview
- Consumer Engagement = UgcScore, TitleMatchScore, ChromeInTotal, SiteImpressions, Subject Impressions, Web site Clicks, Subject Clicks
- Multi-Media Scores = ImageQualityClickSignals, VideoScore, ShoppingScore
- Hyperlinks = TrustedAnchors, SiteLinkIn (avg worth of incoming hyperlinks), PageRank(0,1,2,ToolBar and NR)
Content material Understanding = PageEmbedding, SiteEmbedding, SiteRadius, SiteFocus, TextConfidence, EffortScore
Generalized Method: [(User Interaction Scores + Content Quality Scores + Link Scores) x (Relevance Boost + Quality Boost) + X (content-specific score adjustments)] – (Demotion Rating Mixture)
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Workers authors are listed here.